OpenNMT-py再体验
背景
快速安装OpenNMT。
再体验
硬件要求
深度学习方面,Google著名的开源深度学习框架Tensorflow在1.6版本之后就已经需要一颗支持AVX指令集的CPU了,换言之,它应用了AVX指令集。
另外,AVX-512的大宽度让它很适合用来跑深度学习,所以Intel也针对深度学习设计了一套子指令集——AVX-512 VNNI,用来加速深度学习相关的计算,在测试中,它表现出了相当的实力。
环境要求
最新环境为:
* Python 3.5 or above
* TensorFlow 2.3, 2.4
本文没有使用最新环境,而是选择了一个稳定环境:
* Python 3.6
* tensorflow-gpu==1.12.0
* cuDNN 7
* CUDA 9
环境配置:
安装Conda
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
sh Miniconda3-latest-Linux-x86_64.sh
conda init bash
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
conda create -n nmt python=3.6
安装
升级pip
pip install --upgrade pip
结果
Successfully installed pip-21.0.1
安装tensorflow
python -m pip install tensorflow-gpu==1.12.0 -i https://mirrors.aliyun.com/pypi/simple
结果
Successfully installed absl-py-0.12.0 astor-0.8.1 cached-property-1.5.2 gast-0.4.0 grpcio-1.36.1 h5py-3.1.0 importlib-metadata-3.7.3 keras-applications-1.0.8 keras-preprocessing-1.1.2 markdown-3.3.4 numpy-1.19.5 protobuf-3.15.6 six-1.15.0 tensorboard-1.12.2 tensorflow-gpu-1.12.0 termcolor-1.1.0 typing-extensions-3.7.4.3 werkzeug-1.0.1 zipp-3.4.1
降低numpy版本
pip install numpy==1.16.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
确认安装成功
import tensorflow as tf
print(tf.test.is_gpu_available())
安装OpenNMT-tf
python -m pip install OpenNMT-tf==1.25.3 -i https://mirrors.aliyun.com/pypi/simple
结果
Successfully installed OpenNMT-tf-1.25.3 portalocker-2.0.0 pyonmttok-1.25.0 pyyaml-5.4.1 rouge-0.3.1 sacrebleu-1.5.1
跑英中实验
准备语料
https://github.com/brightmart/nlp_chinese_corpus
生成词典
onmt-build-vocab --size 50000 --save_vocab ch-vocab.txt chen/ch-train.txt --tokenizer CharacterTokenizer
onmt-build-vocab --size 50000 --save_vocab en-vocab.txt chen/en-train.txt
训练
配置文件 data.yml
model_dir: run_transformer/
data:
train_features_file: chen/ch-train.txt
train_labels_file: chen/en-train.txt
eval_features_file: chen/ch-val.txt
eval_labels_file: chen/en-val.txt
source_words_vocabulary: ch-vocab.txt
target_words_vocabulary: en-vocab.txt
基于Transformer的列到序列模型的训练和评估循环。
onmt-main --config data.yml --auto_config --model_type Transformer train_and_eval
结果
INFO:tensorflow:Saving checkpoints for 54584 into run_transformer/model.ckpt.
INFO:tensorflow:Skip the current checkpoint eval due to throttle secs (18000 secs).
INFO:tensorflow:loss = 5.266799, step = 54600 (146.166 sec)
INFO:tensorflow:source_words/sec: 1176
INFO:tensorflow:target_words/sec: 18828
INFO:tensorflow:loss = 5.245619, step = 54700 (143.131 sec)
INFO:tensorflow:source_words/sec: 1193
INFO:tensorflow:target_words/sec: 19227
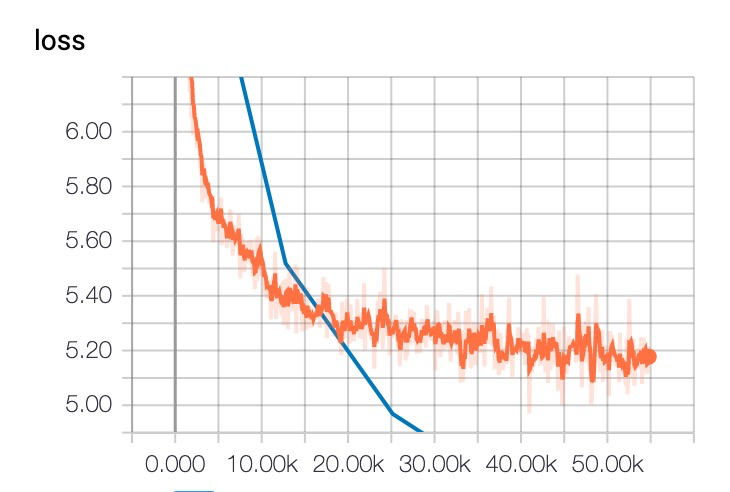
查看训练情况
tensorboard --logdir="."
收敛情况
推理
onmt-main --config data.yml --auto_config --features_file="chen/ch-test.txt" --predictions_file="predict.txt" infer > infer.log 2>&1
结果
<unk> <unk> <unk> <unk> <unk>
<unk> <unk> <unk> <unk> <unk>
<unk> <unk> <unk> <unk> <unk>
<unk> <unk> <unk> <unk> <unk>
<unk> <unk> <unk> <unk> <unk>
好吧,我们失败了!
跑envi实验
实验数据
wget "https://nlp.stanford.edu/projects/nmt/data/iwslt15.en-vi/train.en"
wget "https://nlp.stanford.edu/projects/nmt/data/iwslt15.en-vi/train.vi"
wget "https://nlp.stanford.edu/projects/nmt/data/iwslt15.en-vi/vocab.en"
wget "https://nlp.stanford.edu/projects/nmt/data/iwslt15.en-vi/vocab.vi"
跑toy-ende实验
准备数据
wget https://s3.amazonaws.com/opennmt-trainingdata/toy-ende.tar.gz
tar xf toy-ende.tar.gz
词表
onmt-build-vocab --size 50000 --save_vocab src-vocab.txt toy-ende/src-train.txt
onmt-build-vocab --size 50000 --save_vocab tgt-vocab.txt toy-ende/tgt-train.txt
训练
配置文件 data.yml
model_dir: run/
data:
train_features_file: toy-ende/src-train.txt
train_labels_file: toy-ende/tgt-train.txt
eval_features_file: toy-ende/src-val.txt
eval_labels_file: toy-ende/tgt-val.txt
source_words_vocabulary: src-vocab.txt
target_words_vocabulary: tgt-vocab.txt
基于RNN的小序列到序列模型的训练和评估循环。
onmt-main --config data.yml --auto_config --model_type NMTSmall train_and_eval
结果
2021-03-26 17:13:07.525166: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1511] Adding visible gpu devices: 0
2021-03-26 17:13:07.525230: I tensorflow/core/common_runtime/gpu/gpu_device.cc:982] Device interconnect StreamExecutor with strength 1 edge matrix:
2021-03-26 17:13:07.525243: I tensorflow/core/common_runtime/gpu/gpu_device.cc:988] 0
2021-03-26 17:13:07.525253: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1001] 0: N
2021-03-26 17:13:07.525359: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1115] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 14980 MB memory) -> physical GPU (device: 0, name: Tesla V100-SXM2-16GB, pci bus id: 0000:00:07.0, compute capability: 7.0)
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
INFO:tensorflow:Saving checkpoints for 0 into run/model.ckpt.
INFO:tensorflow:loss = 205.3001, step = 0
INFO:tensorflow:global_step/sec: 8.31761
INFO:tensorflow:loss = 190.56667, step = 100 (12.023 sec)
INFO:tensorflow:global_step/sec: 9.21357
INFO:tensorflow:loss = 201.50346, step = 200 (10.854 sec)
INFO:tensorflow:source_words/sec: 9853
INFO:tensorflow:target_words/sec: 9797
INFO:tensorflow:global_step/sec: 9.18713
INFO:tensorflow:loss = 75.21286, step = 300 (10.885 sec)
INFO:tensorflow:source_words/sec: 13306
INFO:tensorflow:target_words/sec: 13235
INFO:tensorflow:global_step/sec: 9.4137
INFO:tensorflow:loss = 134.90909, step = 400 (10.623 sec)
查看训练结果
tensorboard --logdir="."
结果
TensorBoard 1.12.2 at http://localhost:6006 (Press CTRL+C to quit)
onmt-main支持的类型
- ListenAttendSpell:LAS端到端架构
- NMTBig
- NMTMedium
- NMTSmall
- SeqTagger:
- Transformer
- TransformerAAN: Transformer via an Average Attention Network
- TransformerBig
- TransformerBigFP16
- TransformerFP16:混合精度量化,FP16是FP32运算速度的2倍,INT8是FP32的4倍。
ListenAttendSpell
2017年,谷歌大脑和Speech团队发布最新端到端自动语音识别(ASR)模型,词错率将至5.6%,相比传统的商用方法实现了16%的改进。
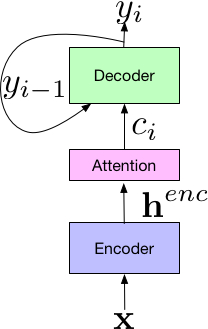
LAS端到端模型的组件