Speech recognition with weighted finite-state transducers阅读
背景
ASR中涉及到的wfst运算有:composition, 确定化determinization和minimization。
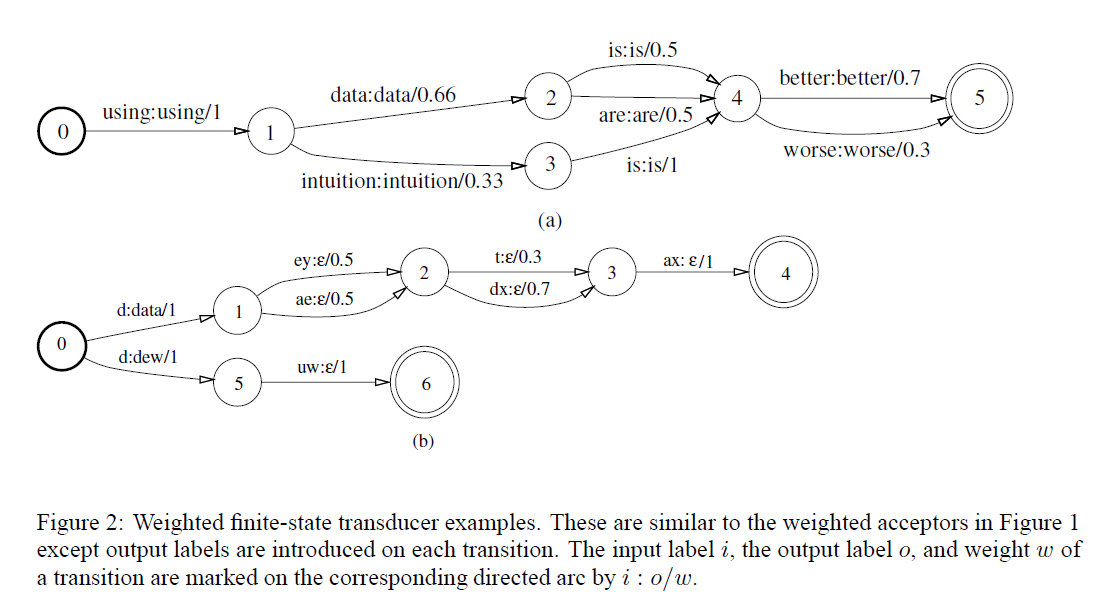
ASR中的WST例子
WFSA例子
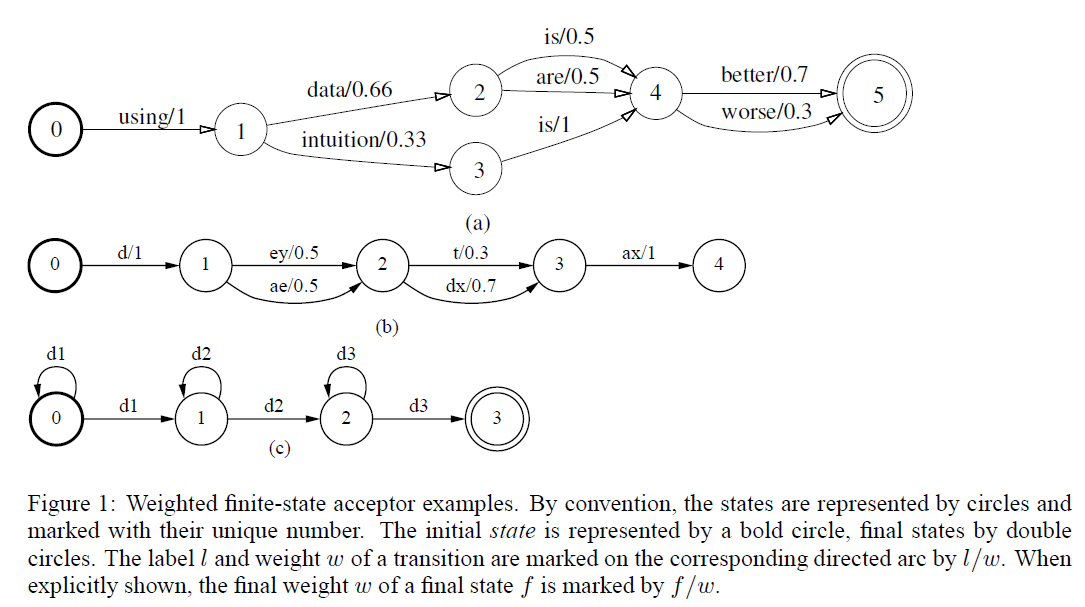
(a)是一个LM的例子,完整路径中的每个子路径都是一个单词,完整路径的概率为每个单词概率的乘积。
(b)是LM模型中,单词data可能的发音。每一个合法的发音,是完整路径中音素的字符串,其概率为每个子路径概率的乘积。
(c)是一个从左向右的,三分布的HMM声学模型,对应着一个音素。完整路径中的label,对应着这个音素的声学分布。
WFST例子
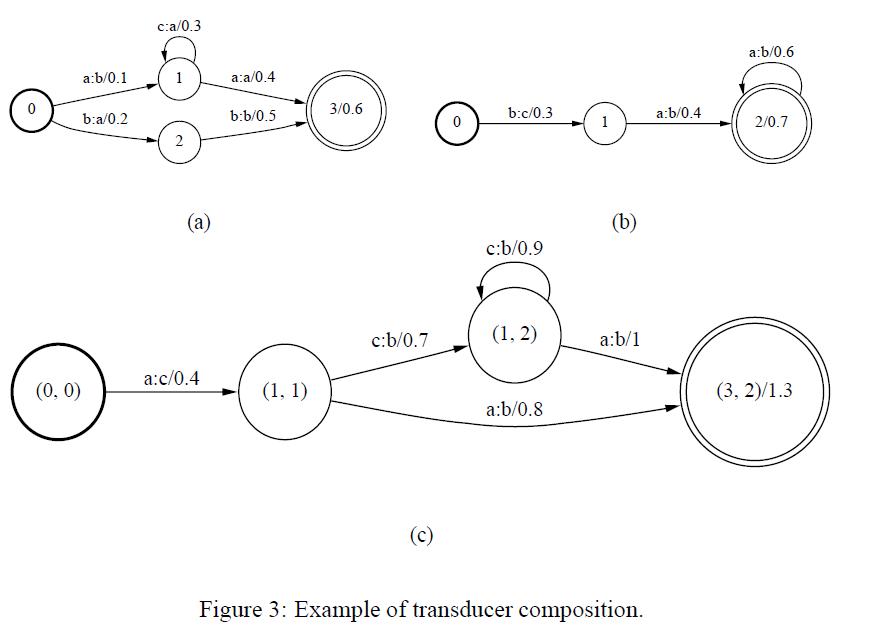
composition
Determinization
两个acceptor等价,指对于相同的input,都有相同的权重;权重的分布情况可以不同,不做要求。
两个transducer等价,指对于相同的input,都有相同的权重和output;权重和output的分布情况可以不同,不做要求。
不是所有的wfst都可以被determinization,但是无环的wfst都可以被determinization。
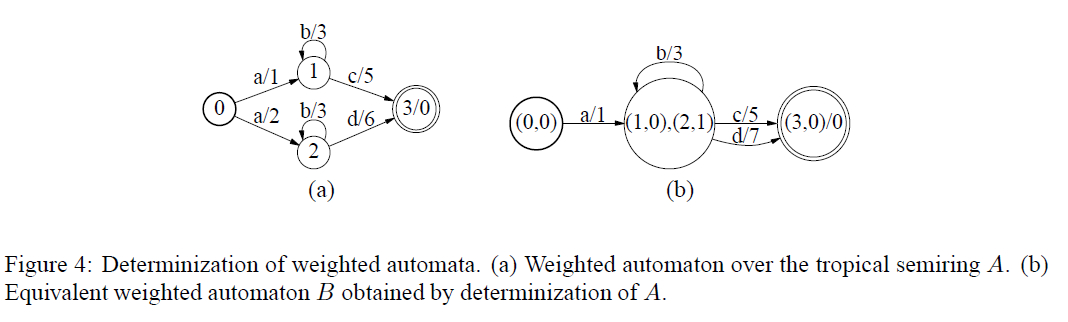
从某个state出发的所有转移,不能有相同的input label。
如果一个WFST是determinizable的,这个WFST必须是Functional的。
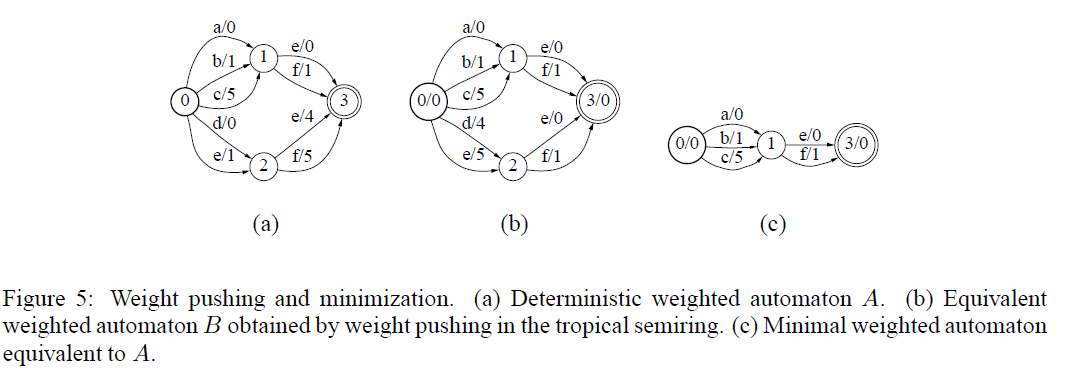
Minimization