Flink 2021记录
背景
回顾Flink 2021的发展情况。
记录
Flink在2021年发了两个大版本,1.13和1.14。
云原生
- 云原生部署模式,自动弹性扩缩容。
- Hive SQL语句兼容,包括DDL/DML/DQL。
易用性
- 完整的批流一体的API (SQL/Table/DataStream): Flink 1.14
- 流批混合运行,数据源自动切换(Hive/Kafka)
- PyFlink:功能和性能追平Java API
基于DataStream做了统一,可以放弃DataSet API了。
Log-Based checkpoint
做snapshot更快。
功能点
流批一体功能演进
Flink 1.14只保留了DataStream API。Connector兼容流式存储和批式存储。
支持流式shuffle框架和批式shuffle框架。
Flink-CDC:全增量一体化数据集成
全增量一体化数据集成(全实时)
MySQL --> Flink CDC --> Hudi
先并行全量,再binlog增量。
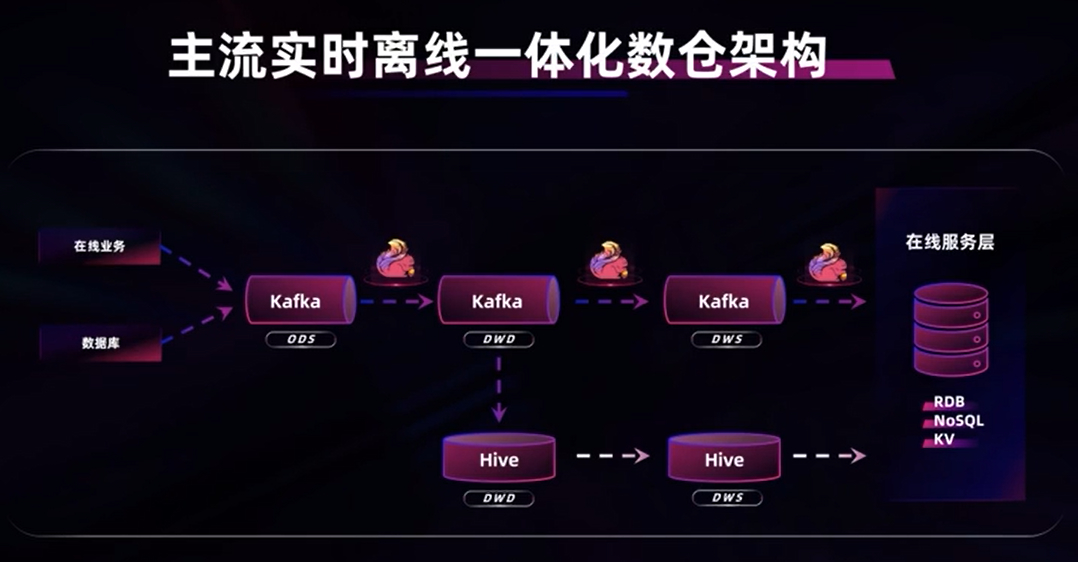
主流实时离线一体化数仓架构
历史架构
流式数仓:实时离线一体化架构
一套API,一套存储体系,一套方法论。
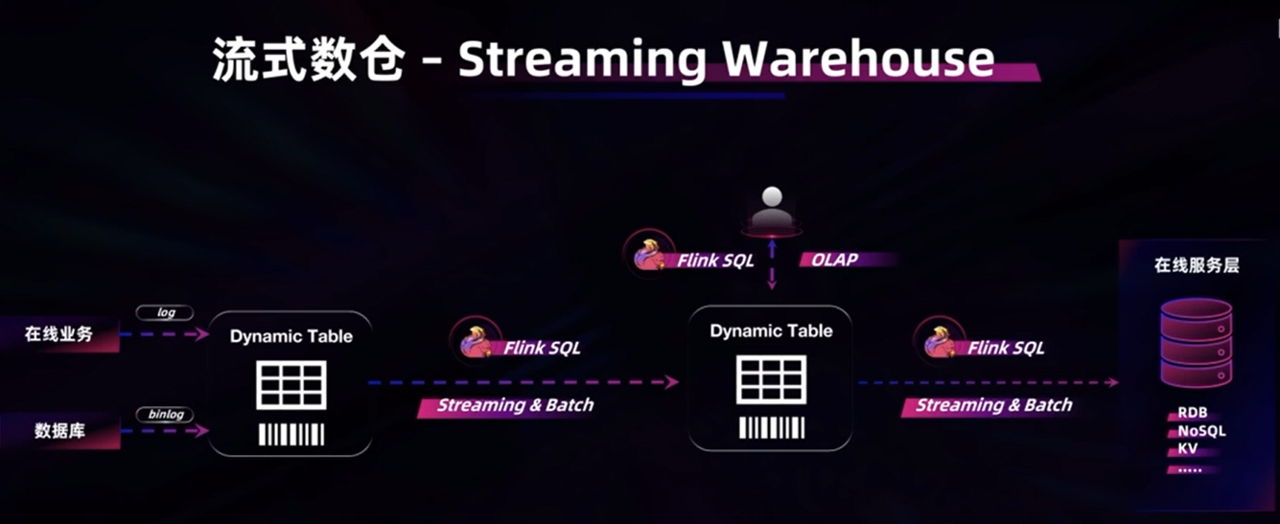
优点:
- 全链路数据实时流动:非minibatch
- 流动的数据皆可分析:
- 实时离线分析一体化:一套API
Flink Dynamic Table:流批一体存储

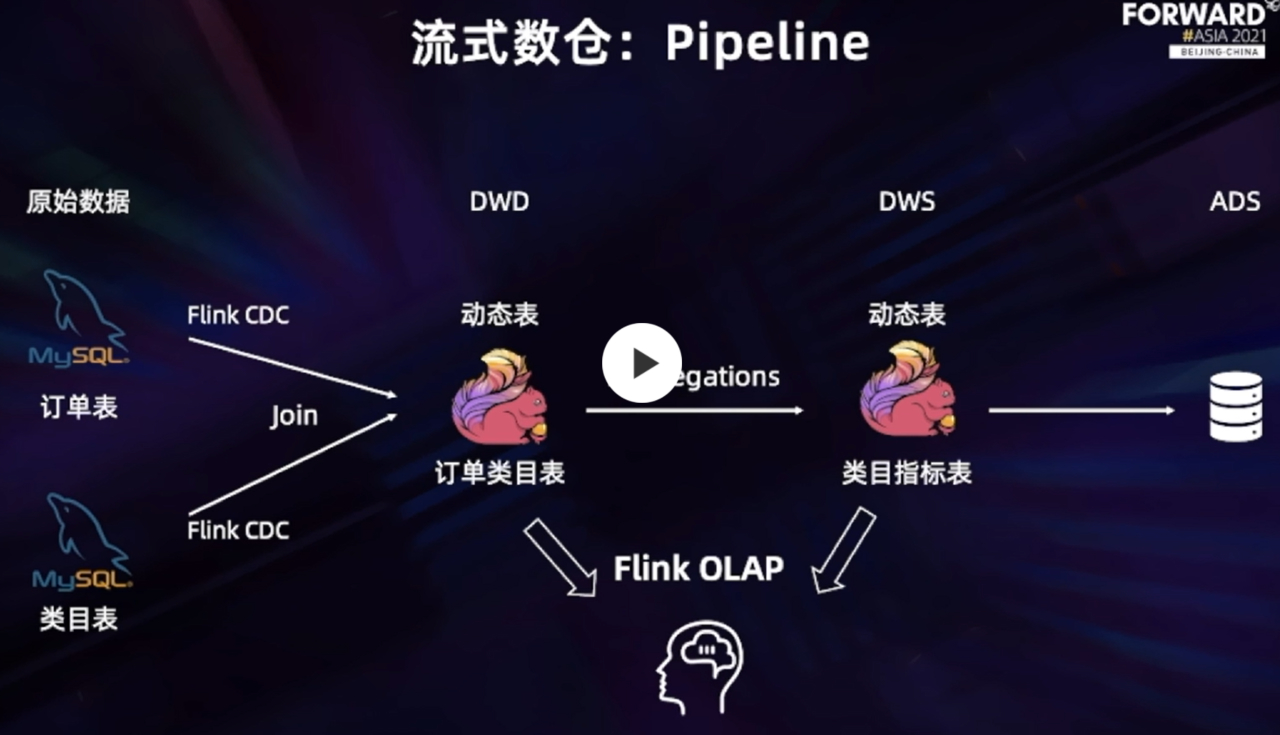
通过Flink SQL进行数据订正。
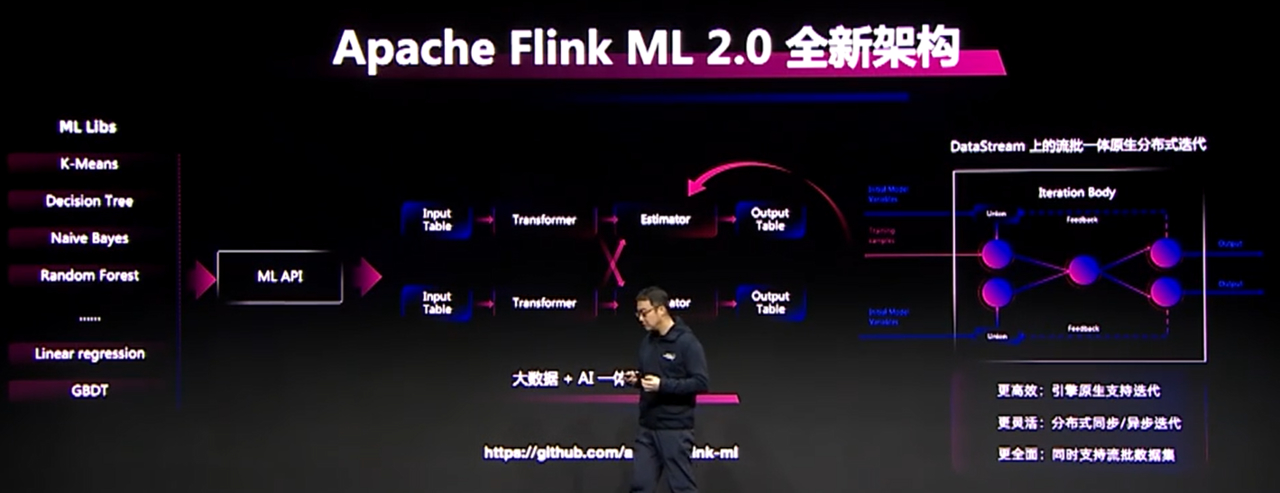
Flink机器学习推荐

ALink项目重新进行打磨,Flink ML 2.0。
FAQ
全局一致性保证
Flink最大的亮点是有状态的全局一致性引擎,基于Chandy-Lamport算法。
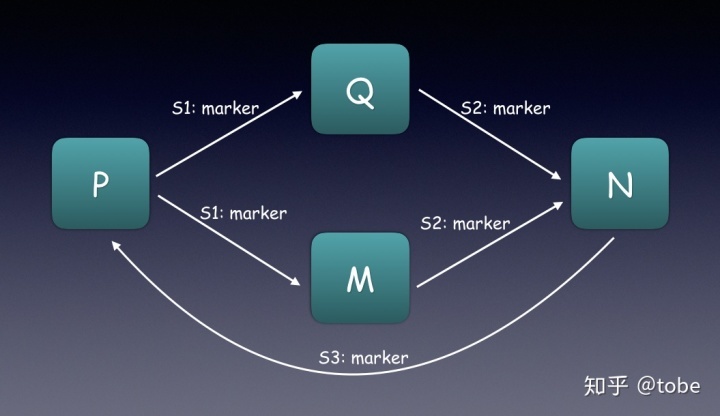
Chandy-Lamport算法
Chandy-Lamport算法要求节点间通信可靠并且消息有序。
让某个节点做global snapshot时发送一个marker,每个节点在处理数据时遇到marker执行下面的判断来做local snapshot,最后所有节点接收到marker并正确处理后就可以组成一个global snapshot。
多输入
在强一致的场景(例如Flink的exactly-once语义),每个节点是需要等待所有input
channel的marker到达后才做local snaphot和处理marker后续数据,因此节点的性能取决于最慢的inputchannel,服务整体吞吐和性能也会降低。
而在非强一致的场景可以,允许节点一直处理input channel中到达的数据,等到所有marker到达才做local snapshot,这样部分marker后的数据也会加到local
snapshot里面,如果节点发生故障从global snapshot恢复后还会继续算这部分marker以后的数据,这也是Flink中在不强制同步marker处理只能保证at-least-once语义的原因,当然这样服务的吞吐和性能会更高。
其它
相关工具
- zeppelin:基于Web的notebook,提供交互数据分析和可视化。
- AIFlow:AI工作流平台。
参考
- Flink Asia 2021中王峰的演讲。
- Chandy-Lamport算法核心解读