ClickHouse查询性能分析
背景
遇到了ClickHouse中查询慢的情况,记录下优化过程。
基础知识
MergeTree引擎原理
MergeTree引擎与LSM Tree相比,去掉了MemTable和Log。
向MergeTree引擎表插入数据时,数据不经过缓冲直接写到磁盘。

parts
parts信息存储在系统表中,如下:
SELECT
partition,
name,
part_type,
active
FROM system.parts
WHERE table = 'us_stock'
Query id: f01fbc5f-f761-4e46-b4c3-feaa2e9c3df5
┌─partition─┬─name──────────────────────┬─part_type─┬─active─┐
│ tuple() │ all_2883_12950_33 │ Wide │ 1 │
│ tuple() │ all_12951_14442_37 │ Wide │ 1 │
│ tuple() │ all_14443_748892_91738 │ Wide │ 1 │
│ tuple() │ all_748893_876847_82252 │ Wide │ 1 │
│ tuple() │ all_876848_1088563_88880 │ Compact │ 1 │
│ tuple() │ all_1088564_1105482_15775 │ Compact │ 1 │
│ tuple() │ all_1105483_1105484_1 │ Compact │ 1 │
└───────────┴───────────────────────────┴───────────┴────────┘
parts有两种类型,Wide和Compact。
在较新的版本中,ClickHouse使用了Polymorphic机制。新写入数据为整体存储Compact,新数据为列存储Wide。
part名称,一般格式为 partition_min_block_number_max_block_number_level。
level表示这个part经过了几次merge,每merge一次会更新生成一个level+1后的part目录。
如果经过mutate操作,则还会有data_version的后缀。
partition_min_block_number_max_block_number_level_data_version。
compact存储
compact存储(如all_1088564_1105482_15775)下的文件结构为:
190 checksums.txt
138 columns.txt
5 count.txt
365K data.bin // 数据文件
480 data.mrk3 // 索引标记文件
10 default_compression_codec.txt
30 primary.idx
wide存储
wide存储(如all_2883_12950_33)下的文件结构为:
639 checksums.txt
78M close.bin
79K close.mrk2
138 columns.txt
8 count.txt
16M date.bin
79K date.mrk2
10 default_compression_codec.txt
77M high.bin
79K high.mrk2
77M low.bin
79K low.mrk2
596K name.bin
79K name.mrk2
78M open.bin
79K open.mrk2
22K primary.idx
99M volume.bin
79K volume.mrk2

一个列存文件是一个个小的压缩数据块组成的。一个压缩数据块中可以包含若干个granule的数据,而granule就是Clickhouse中最小的查询数据集,后面的索引以及标记也都是围绕granule来实现的。granule的大小由配置项index_granularity确定,默认8192。
compact存储到wide存储之间的转换
转换的目的是为了减少IO操作。
如果数据量很小,使用compact存储会更优。
如果数据量很大,使用wide存储会更优。
- min_bytes_for_wide_part:数据从合并存储(Compact)转成按列存储(Wide)的最小文件大小。
- min_rows_for_wide_part:数据从合并存储(Compact)转成按列存储(Wide)的最小行数。
建表时可以指定大小:
CREATE TABLE demo.sample_table
(
`id` int,
`name` String,
`birth` date
)
ENGINE = MergeTree
ORDER BY id
SETTINGS min_bytes_for_wide_part = 10240
也可以修改大小:
ALTER TABLE demo.sample_table
MODIFY SETTING min_rows_for_wide_part = 5;
数据查询方式
查询时应该如何从不同的列存文件中查找到同属于某一行的数据?
前提:使用MergeTree系列的表引擎,指定一个排序键,由一列或多列组成。在数据写入磁盘文件中时,数据行的就会按照制定的顺序排列,随后按列拆分写入各个列存文件中。
在查询时,会根据最左原则,来使用排序键。如下图所示:

Clickhouse设计了数据标记文件,帮助我们更高效地获取到每行数据在列存文件中的具体位置。
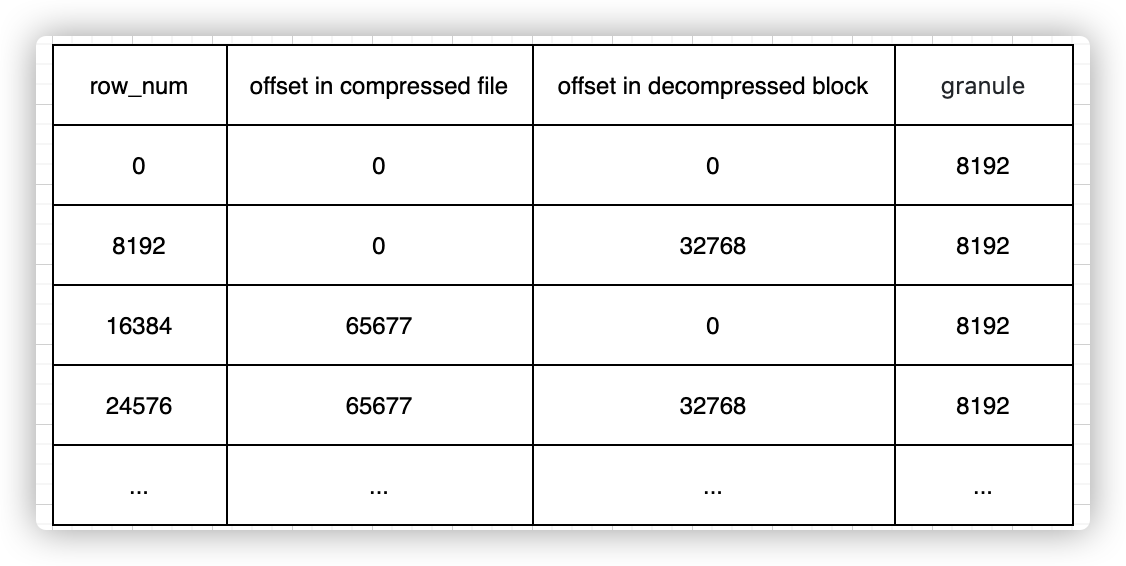
// 数据索引文件,存储的是一个个主健的值,这里主键只有一列
root@clickhouse-0:20210110_0_123_3_341# od -l -j 0 -N 80 --width=8 primary.idx
0000000 5670735277560
0000010 24176312979802680
0000020 48658950580167724
0000030 72938406171441414
0000040 96513037981382350
0000050 120656338641242134
0000060 145024009883201898
0000070 169438340458750532
0000100 193384698694174670
0000110 217869890390743588
// 数据标记文件,可以看作三列,分别是数据压缩块位置,数据块内偏移和granule大小
root@clickhouse-0:20210110_0_123_3_341# od -l -j 0 -N 240 --width=24 ./value9.mrk2
0000000 0 0 8192
0000030 0 32768 8192
0000060 65677 0 8192
0000110 65677 32768 8192
0000140 129357 0 8192
0000170 129357 32768 8192
0000220 193106 0 8192
0000250 193106 32768 8192
0000300 258449 0 8192
0000330 258449 32768 8192
查看执行计划和客户端查询日志
新版本的ClickHouse可以直接使用
EXPLAIN SELECT
和
EXPLAIN SYNTAX SELECT
旧版本的ClickHouse不支持EXPLAIN,只能通过日志间接的读取SQL的查询计划,方法如下[6]:
clickhouse-client -h <host> --port <port> --password <pass> --send_logs_level=trace <<< "
// SQL statement here
" > /dev/null
增加Data Skipping索引
二级索引在clickhouse中又称之为跳数索引,目前拥有minmax,set,ngrambf_v1,tokenbf_v1和bloom_filter五种类型。
ALTER TABLE [db].name ADD INDEX name expression TYPE type GRANULARITY value [FIRST|AFTER name]- Adds index description to tables metadata.ALTER TABLE [db].name DROP INDEX name- Removes index description from tables metadata and deletes index files from disk.
示例
alter table us_stock_local on cluster default add index name_bf (name) TYPE bloom_filter GRANULARITY 1;
alter table us_stock_local on cluster default add index time_minmax (time) TYPE minmax GRANULARITY 4;
注意事项[7]:
- 索引只对新加入的数据生效
- 历史数据,需要优化后才可以生效,方法如下:
OPTIMIZE TABLE us_stock_local FINAL;
或者 [8]
alter table us_stock_local on cluster default MATERIALIZE INDEX time_minmax in partition '2022-01-21'
参考
- ClickHouse MergeTree变得更像LSM Tree了?——Polymorphic Parts特性浅析
- ClickHouse InterpreterSelectQuery 原理之 query stage
- Clickhouse 合并存储提高小数据量的处理性能表参数min_bytes_for_wide_part和min_rows_for_wide_part
- ClickHouse解析
- ClickHouse主键探讨[译文+补充]
- 解读ClickHouse日志中的SQL查询计划
- Clickhouse: how to use
Data Skipping IndexesandManipulations With Data Skipping Indicesfeatures in clickhouse? - 【转载】百分点大数据技术团队:ClickHouse国家级项目性能优化实践