模型结构发展历史
背景
概况
传统语音识别:基于统计的方法,在GMM-HMM混合结构上进行训练。
深度学习方法:CNN、RNN,有效提取特征,建立声学模型。
端到端方法:避免多个模型间的误差传导,有CTC技术和attention技术。
声学模型
| 方法 | 时间 | 描述 | 特点 | 不足 |
|---|---|---|---|---|
| HMM(隐马尔科夫模型) | 1980+ | 统计模型方法 | 描述语言信号短时平稳特征,将声学、语言句、句法统一 | N/A |
| GMM(高斯混合模型) | 对语音的观察概率建模 | |||
| ANN(人工神经网络) | 80年代后期 | DNN前身 | 浅层神经网络效果一般 | |
| DBN(深度置信网络) | 2006 | 训练过程中容易陷入局部最优 | N/A | |
| DNN(深度神经网络) | 2001 | 成功用于大词汇量连续语音识别,取代GMM-HMM | N/A | |
| FDNN(前馈型深度神经网络) | ||||
| RNN(循环神经网络) | 在隐层上增加一个反馈连接,当前层包括上一层输出和前一时刻隐层输出 | 更强的长时建模能力,具有记忆功能 | 训练时会梯度消失,容易过拟合,难以训练 | |
| LSTM(长短时记忆)RNN | 使用输入门、输出门和遗忘门 | 在相对更长时间内稳定传播 | ||
| BLSTM-RNN | 利用历史的语音信息和未来的语音信息 | 时延较大,不适合实时系统 | ||
| LC-BLSTM(延时受控BLSTM) | 前向LSTM不变,反向LSTM做了优化,使用最多N帧前瞻量的反向LSTM | |||
| 行卷积 BLSTM | 前向LSTM不变,反向LSTM做了优化,使用N帧前瞻量的行卷积 | |||
| FSMN(前馈型序列记忆网络) | 采用非循环的前馈结构 | 180ms时延,效果和BLSTM-RNN相当 | ||
| CNN(卷积神经网络) | 卷积运算,另一种可以有效利用长时上下文语境信息的模型 | 解决频率轴多变性 | ||
| CNN-HMM | CNN-HMM +DNN层 | 固定长度语音帧,不能看到足够的上下文, 卷积层数少1-2层 | ||
| CNN-LSTM-DNN(CLDNN) | LSTM +RNN层 | |||
| DFCNN(全序列卷积神经网络) | 2016 | 把语谱图看作带有特定模式的图像 | 比BLSTM-CTC提升15% | SGD(随机梯度下降)收敛慢,训练慢 |
| attention | 2014 | 注意力机制 encoder-decoder |
语言模型
| 方法 | 时间 | 描述 | 特点 | 不足 |
|---|---|---|---|---|
| N-gram | 统计语言模型 | 结构简单,训练效率高 | 随阶数和词表指数增长,无法使用更高阶数,性能容易瓶颈 | |
| RNN | 标准的RNN | 处理任意长度的历史信息 | 训练耗时,在100G~1TB语料上几乎不可实现 | |
| LSTM | 标准 LSTM | 解决了RNN训练过程中的梯度消失问题 |
发展历史
HMM
20世纪80年代开始,以隐马尔科夫模型(HMM, hidden Markov model)方法为代表的基于统计模型方法,能够很好的描述语音信号的短时平稳特征,并且将声学、语言学、句法等知识集成到统一框架中。
GMM-HMM
第一个“非特定人连续语音识别系统”是当时还在卡耐基梅隆大学读书的李开复研发的SPHINX[4]系统,其核心框架就是 GMM-HMM 框架,其中 GMM( Gaussian mixture model,高斯混合模型)用来对语音的观察概率进行建模, HMM则对语音的时序进行建模。
DNN
20 世纪 80 年代后期,深度神经网络( deep neural network, DNN)的前身——人工神经网络( artificial neural network,
ANN)也成为了语音识别研究的一个方向[5]。但这种浅层神经网络在语音识别任务上的效果一般,表现并不如 GMM-HMM 模型。
DBN
2006 年 Hinton[7]提出使用受限波尔兹曼机( restricted Boltzmann machine, RBM)对神经网络的节点做初始化,即深度置信网络( deep belief network, DBN)。 DBN 解决了深度神经网络训练过程中容易陷入局部最优的问题,自此深度学习的大潮正式拉开。
2011年
2009 年, Hinton 和他的学生Mohamed D[8]将 DBN 应用在语音识别声学建模中,并且在 TIMIT 这样的小词汇量连续语音识别数据库上获得成功。 2011 年 DNN 在大词汇量连续语音识别上获得成功[9],语音识别效果取得了近 10 年来最大的突破。
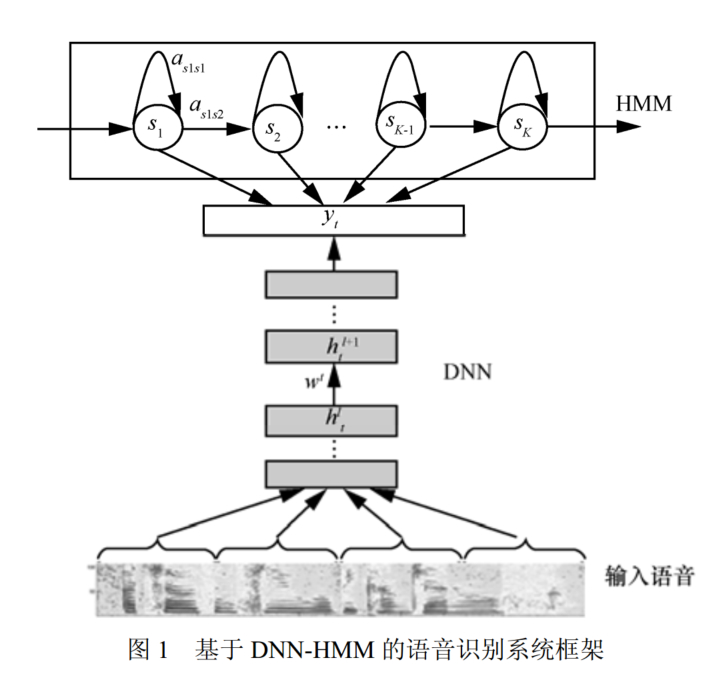
使用 DNN 取代 GMM 主要有以下几个原因:
- DNN 可以将相邻的语音帧拼接起来作为输入特征,使得更长时的结构信息得以描述;
- DNN 的输入特征可以是多种特征的融合,也可以是离散或者连续的特征;
- 不需要对语音数据分布进行假设,也是使用 DNN估计 HMM状态的后验概率分布的一个特点。
加窗分帧
语音识别的特征提取需要首先对波形进行加窗和分帧,然后再提取特征。
训练 GMM 模型的输入是单帧特征, DNN 则一般采用多个相邻帧拼接在一起作为输入,这种方法使得语音信号更长的结构信息得以描述,研究表明,特征拼接输入是 DNN相比于 GMM可以获得大幅度性能提升的关键因素。
由于说话时的协同发音的影响,语音是一种各帧之间相关性很强的复杂时变信号,正要说的字的发音和前后好几个字都有影响,并且
影响的长度随着说话内容的不同而时变。虽然采用拼接帧的方式可以学到一定程度的上下文信息,但是由于 DNN 输入的窗长(即拼接的帧数)是事先固定的, 因此 DNN 的结构只能学习到固定的输入到输入的映射关系,导致其对时序信息的更长时相关性的建模灵活性不足。
RNN
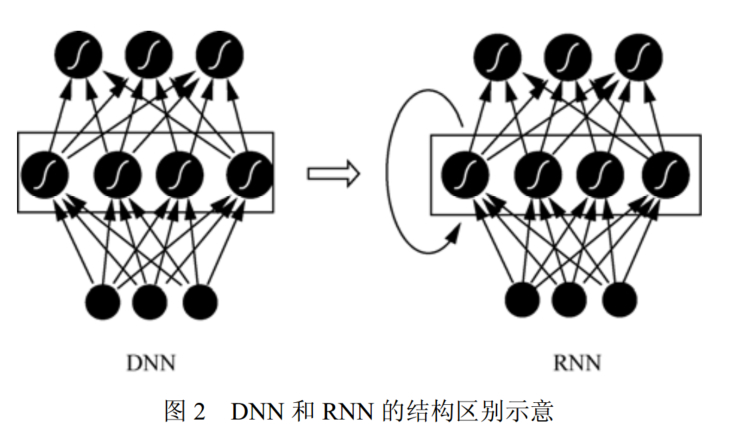
语音信号具有明显的协同发音现象,因此必须考虑长时相关性 。 由于循环神经网络( recurrent neural network, RNN)具有更强的长时建模能力,使得 RNN 也逐渐替代 DNN 成为语音识别主流的建模方案。
DNN 和 RNN 的网络结构如图 2 所示, RNN 在隐层上增加了一个反馈连接,是其和 DNN 最大的不同。这意味着RNN 的隐层当前时刻的输入不但包括了来自上一层的输出,还包括前一时刻的隐层输出,这种循环反馈连接使得 RNN 原则上可以看到前面所有时刻的信息,这相当于 RNN 具备了历史记忆功能。对于语音这种时序信号来说, 使用 RNN建模显得更加适合。
LSTM
FSMN
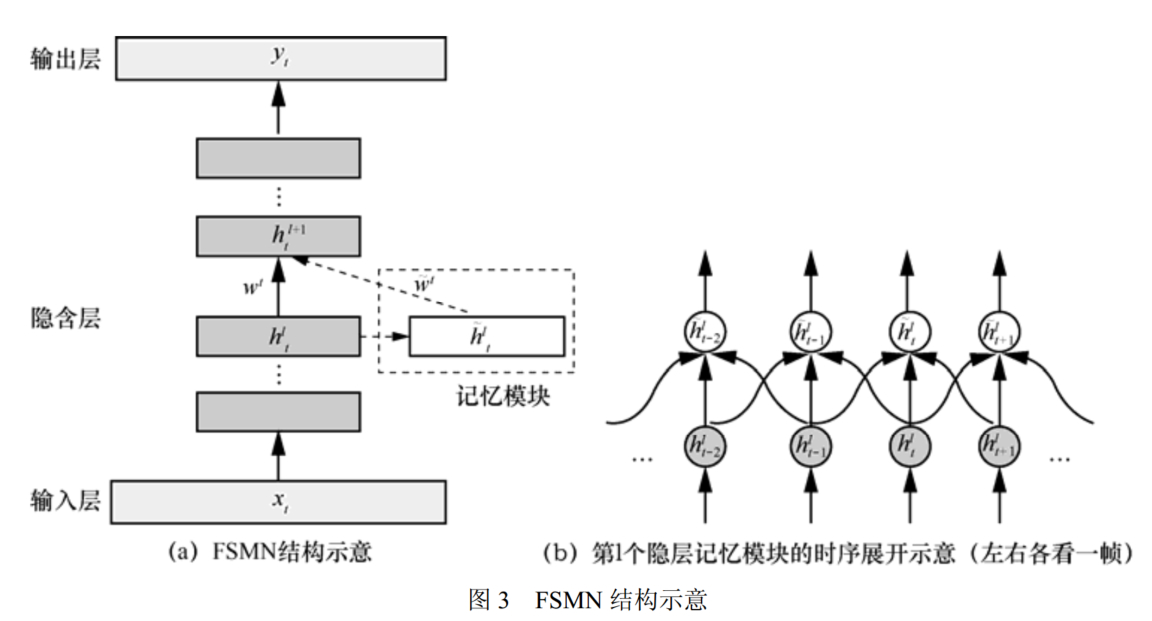
左右各看一帧
CNN
DFCNN
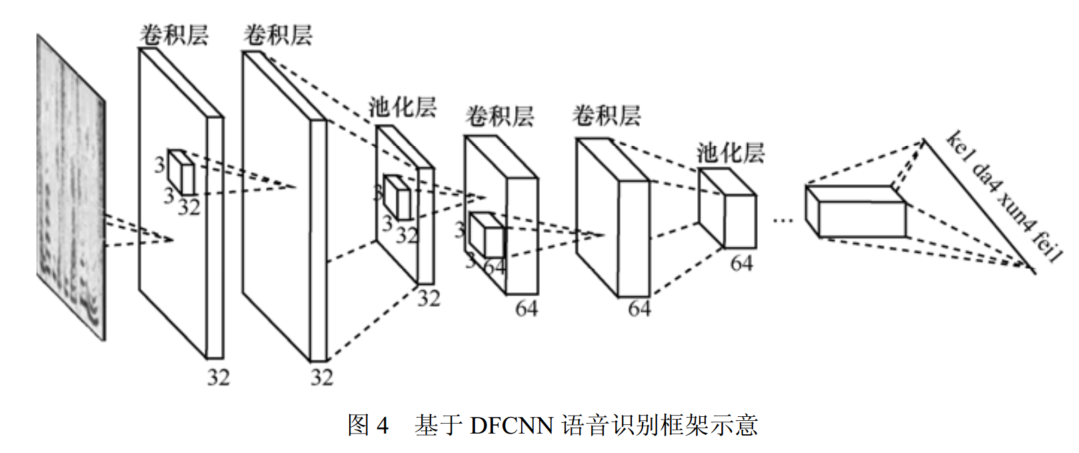
首先,在输入端,传统语音识别系统的提取特征方式是在傅里叶变换后用各种类型的人工设计的滤波器,比如 Log Mel-Filter Bank,造成在语音信号频域,尤其是高频区域的信息损失比较明显。
另外,传统语音特征采用非常大的帧移来降低运算量,导致时域上的信息会有损失,当说话人语速较快的时候,这个问题表现得更为突出。而DFCNN 将语谱图作为输入, 避免了频域和时域两
个维度的信息损失,具有天然的优势。
其次,从模型结构上来看,为了增强 CNN 的表达能力,DFCNN 借鉴了在图像识别中表现最好的网络配置,与此同时,为了保证 DFCNN 可以表达语音的长时相关性,通过卷积池化层的累积, DFCNN能看到足够长的历史和未来信息,有了这两点,和 BLSTM 的网络结构相比, DFCNN 在顽健性上表现更加出色。
最后,从输出端来看, DFCNN 比较灵活,可以方便地和其他建模方式融合,比如和连接时序分类模型 (connectionist temporal
classification, CTC)方案结合,以实现整个模型的端到端声学模型训练。
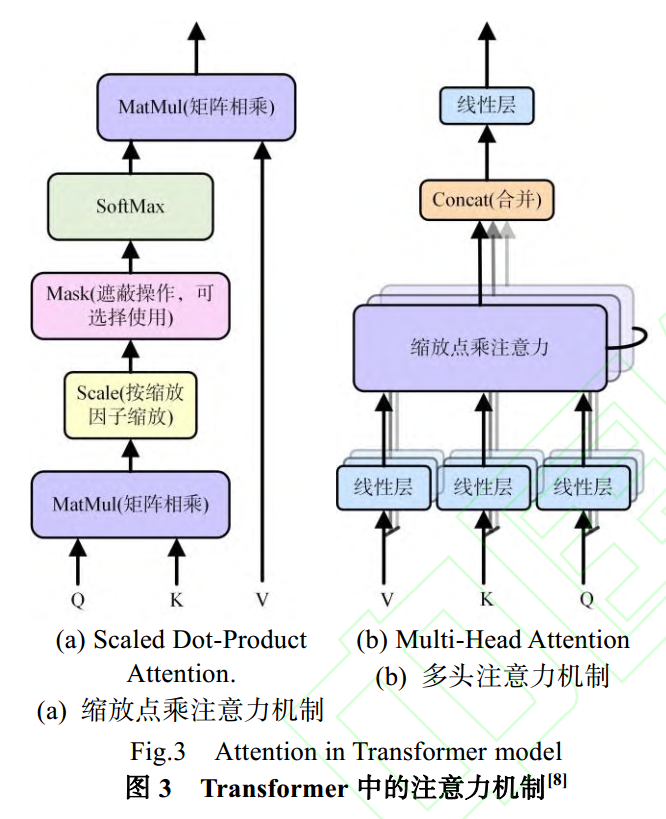
Transformer
优化手段
常用
- 采用大的建模单元,如子词或词,这样的建模单元更加稳定并且有助于语言建模。
- label smoothing 方法来避免模型对于预测结果过于自信。
- 使用最小化词错误率的方式进行区分性训练。
- 模型除了训练和推理过程训练时通常使用CE, 而在评价阶段使用 WER 等
网络结构
- 深层Transformer:对编码器和解码器使用 48 个 Transformer 层训练, 使用随机残差连接
- Jasper 模型, 其使用了一维卷积, 批归一化, ReLU 激活, dropout 和残差连接, 同时引入了一个称为 NovoGrad 的分层优化器. 通过实验, 最多使用了 54 个卷积层的模型系取得了良好的结果
未来
复杂噪声环境下的语音识别
语音分离:
- 去噪:干扰为非语音噪声,称为语音增强
- 分离:干扰为其他说话人,称为多说话人分离
- 解混响:干扰为目标说话人自身的反射波,称为解混响