基于深度学习算法的语音识别的本机复现环境搭建
背景
华为云学院上提供了一个免费的实验,《基于深度学习算法的语音识别》,利用新型的人工智能(深度学习)算法,结合清华大学开源语音数据集THCHS30进行语音识别的实战演练,让使用者在了解语音识别基本的原理与实战的同时,更好的了解人工智能的相关内容与应用。
通过这个实验,可以了解如何使用Keras和Tensorflow构建DFCNN的语音识别神经网络,并且熟悉整个处理流程,包括数据预处理、模型训练、模型保存和模型预测等环节。
初体验
准备工作
数据:清华大学开源语音数据集THCHS30
wget https://sandbox-experiment-resource-north-4.obs.cn-north-4.myhuaweicloud.com/speech-recognition/data.zip;
wget https://sandbox-experiment-resource-north-4.obs.cn-north-4.myhuaweicloud.com/speech-recognition/data_thchs30.tar
环境:windows + tensorflow 1.13.1 + python 3.7 (原文为3.6,我升级到了3.7)
conda create -n cnnctc37 python=3.7
python -m pip install --upgrade pip -i https://mirrors.aliyun.com/pypi/simple
python -m pip install tensorflow==1.13.1 keras==2.2.4 keras-preprocessing==1.1.0 h5py==2.8.0 numpy==1.19.1 -i https://mirrors.aliyun.com/pypi/simple
使用avx指令集的tensorflow,打开tensorflow-windows-wheel,下载后更名为:tensorflow-1.13.1-cp37-cp37m-win_amd64.whl
python -m pip install tensorflow-1.13.1-cp37-cp37m-win_amd64.whl keras==2.2.4 keras-preprocessing==1.1.0 h5py==2.8.0 numpy==1.19.1 -i https://mirrors.aliyun.com/pypi/simple --force-reinstall
后面的略,全部代码和过程可以看华为云上的实验手册。
模型结构
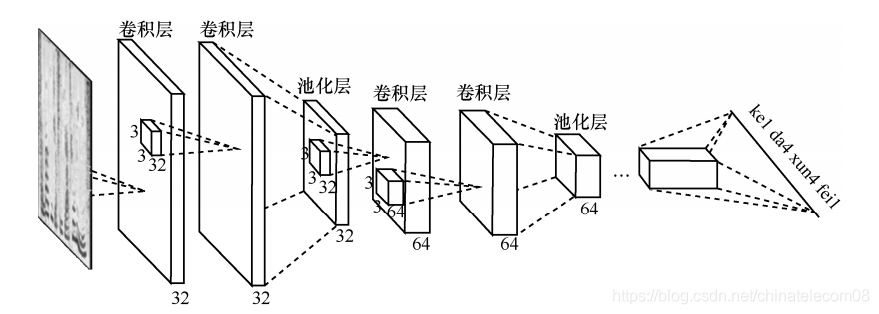
此模型为:CNN + DNN + CTC
- CNN: 4个
- DNN: 2个
- CTC: loss
将h5模型转换为ONNX
依赖
# python -m pip install keras2onnx -i https://mirrors.aliyun.com/pypi/simple
代码
import keras
import keras2onnx
import onnx
from keras.models import load_model
model = load_model('/home/fw/work/2021/02.dnnctc37/asr-model.h5')
onnx_model = keras2onnx.convert_keras(model, model.name)
temp_model_file = '/home/fw/work/2021/02.dnnctc37/asr-model.onnx'
onnx.save_model(onnx_model, temp_model_file)
结果
save file: the model was *not* compiled. Compile it manually.
warnings.warn('No training configuration found in save file: '
The ONNX operator number change on the optimization: 79 -> 36